谷歌机器人迈入「交互语言」新纪元!开放命令正确率高达93.5%,开源数据量提升十倍


新智元报道
编辑:LRS
【新智元导读】Google机器人最近实现了在开放词汇的条件下执行自然语言命令,真正实现了「听懂人话」,相关数据集已开源!
注意看,眼前的这个男人正在对着一个机器人不断发出自然语言指令,如「把绿色的星推到红色块之间」、「把蓝色的方块移动到左下角」,机器人对每一次输入的指令都可以实时完成。
自上世纪60年代开始,机器人专家就开始尝试让机器人听懂人的「自然语言指令」,并执行具体的行动。
理想情况下,未来的机器人将对用户能够用自然语言描述的任何相关任务做出实时反应。
特别是在开放的人类环境中,用户可能需要在机器人行为发生时自定义行为,提供快速纠正,比如「停止,将手臂向上移动一点」或是指定限制「慢慢向右移动」。

此外,实时语言可以使人和机器人更容易在复杂的长期任务中进行协作,人们可以迭代和交互式地指导机器人操作,偶尔会有语言反馈。
目前的相关工作大体可以分为以下三部分:
1、机器人本体需要存在于现实世界;
2、能够响应大量且丰富的自然语言命令;
3、能够执行交互式的(interactive)语言命令,即机器人需要在任务执行的过程中接受新的自然语言指令。
对于第三点来说,目前机器人领域在交互式方面的发展速度仍然非常缓慢,也让机器人缺乏「生命感」。
最近Google发表了一篇论文,提出了一个全新的框架,可以生产真实世界的、实时交互的、执行自然语言指令的机器人,并且相关数据集、环境、基准测试和策略都已开放使用。

论文链接:https://arxiv.org/pdf/2210.06407.pdf
项目主页:https://interactive-language.github.io/
通过对几十万个语言标注轨迹的数据集进行行为克隆训练,产生的策略可以熟练地执行比以前的工作实现了多一个数量级的命令。在现实世界中,研究人员估计该方法在87000个不同的自然语言字符串上有93.5%的成功率。

并且同样的策略能够被人类通过自然语言进行实时引导,以解决广泛的精确的长距离重新排列目标,例如 「用积木做一个笑脸」等。
随论文共同发布的数据集包括近60万个语言标记的轨迹,比之前的可用数据集也要大一个数量级。
交互式语言:与机器人实时对话
想要让机器人融入现实世界中,最重要是能够处理开放式的自然语言指令,但从机器学习的角度来看,让机器人学习开放词汇表语言是一个巨大的挑战。
开放代表模型需要执行大量任务,包括小的纠正指令等。现有的多任务学习设置利用精心设计的模仿学习数据集或复杂的强化学习奖励功能来驱动每个任务的学习,通过这种方式设计的预定义集合注定不会很大。

因此,在开放词汇表任务中一个关键的问题是: 应该如何扩展机器人数据的收集过程,使其能够涵盖真实环境中成千上万的行动,以及如何将所有这些行为与最终用户可能实际提供的自然语言指令联系起来?
在交互式语言中,Google提出的大规模仿真学习框架关键是创建大型、多语言条件的机器人演示数据集的可伸缩性。
和以前设置中需要定义所有的技能,然后收集每个技能策划的示范不同的是,研究人员不断在跨多个机器人在无场景重置(scene resets)或低级别技能分割(low level skill segmentation)的情况下收集数据。
所有的数据,包括失败的数据(如把块从桌子上敲下来 knocking blocks off a table),都要经过一个hindsight language relabeling的过程才能与文本配对。
在这个过程中,标注人员需要观看长长的机器人视频来识别尽可能多的行为,标记每个行为的开始和结束时间,并使用无限制形式的自然语言来描述每个片段。
最重要的是,与之前设置的引导相比,所有用于训练的技能都是从数据本身自下而上显示出来的,而非由研究人员预先确定的。
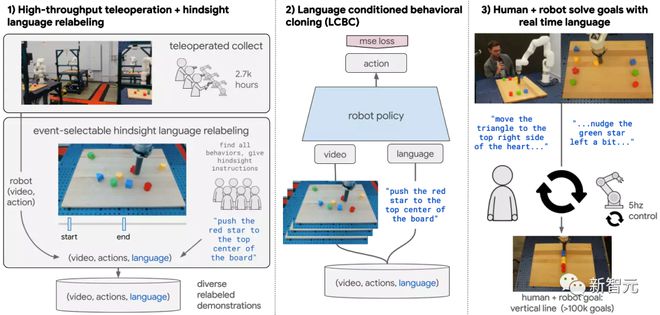
研究人员有意将学习方法和架构尽可能简化,机器人策略网络是一个交叉注意力Transformer,将5赫兹的视频和文本映射到5赫兹的机器人动作,在没有辅助损失(auxiliary losses)的情况下使用标准的监督式学习行为克隆目标。
在测试时,新的自然语言命令可以通过speech-to-text以高达5赫兹的速率发送到策略网络中。
开源基准
在标注过程中,研究人员收集了一个Language-Table数据集,其中包含超过44万实际和18万模拟的机器人执行自然语言命令的演示,以及机器人在演示过程中采取的动作顺序。
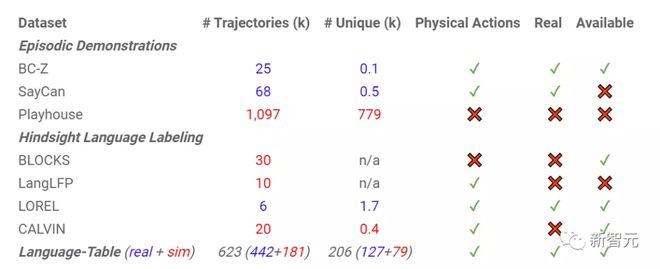
这也是当下最大的基于语言条件的机器人演示(language-conditioned robot demonstration)数据集,直接提升了一个数量级。
Language-Table 推出了一个模拟仿真学习基准,可以用它来进行模型选择,或者用来评估不同方法训练得到的机器人执行指令的能力。
实时语言行为学习
在实验中,研究人员发现,当机器人能够跟随实时输入的自然语言指令时,机器人的能力就会显得特别强大。
在项目网站中,研究人员展示了用户可以仅使用自然语言就能引导机器人通过复杂的长视野序列(long-horizon sequences)来解决需要较长时间才能精确协调控制的目标。

比如在桌子上有许多blcoks,命令可以是「用绿眼睛做一个笑脸」或者「把所有的放在一条垂直线上」等。
因为机器人被训练去跟随开放的词汇语言,所以在实验中能够看到机器人可以对一系列不同的口头修正做出反应,如「轻轻地向右移动红色的星星」。

最后,研究人员探索了实时语言的优势,例如可以让机器人数据采集变得更加高效,一个人类操作员可以同时使用口头语言控制四个机器人,有可能在未来扩大机器人数据收集的规模,而不需要为每个机器人配备一个标注员。
结论
虽然该项目目前仅限于桌面上的一套固定的物体,但交互式语言的实验结果可以初步表明,大规模模仿学习确实可以生产出实时交互式机器人,能够遵循自由形式的终端用户命令。
为了推动物理机器人实时语言控制技术的进步,研究人员开源了Language-Table,也是目前最大的基于语言条件下的真实世界机器人演示数据集,也可以作为相关的模拟基准。
研究人员认为,这个数据集的作用可能不仅仅局限于机器人控制领域,而且可能为研究语言和动作条件视频预测、机器人视频条件语言建模,或者在更广泛的机器学习环境中研究其他许多有趣的活跃问题提供一个新起点。
参考资料:
https://ai.googleblog.com/2022/12/talking-to-robots-in-real-time.html