万字整理:AI绘画突飞猛进的一年半


本文来自微信公众号:Web3天空之城(ID:gh_a702b8d21cdf),作者:城主,原文标题:《AI绘画何以突飞猛进?从历史到技术突破,一文读懂火爆的AI绘画发展史》,题图由作者使用AI绘画生成
前言
自从前段时间偶然间被当下AI绘画的水平震住之后(超越一切的AI作画神器, 和它创作的234个盔甲美女未来战士),作者深感当今AI绘画的飞速进展或许已远超所有人的预期。而这里的前因后果,包括AI绘画的历史,以及最近的突破性进展,值得好好和大伙儿梳理和分享一下。
2022,进击的AI绘画
今年以来,输入文本描述自动生成图片的AI绘画神器突然雨后春笋的冒了出来。
首先是Disco Diffusion。Disco Diffusion 是在今年 2 月初开始爆红的一个 AI 图像生成程序,它可以根据描述场景的关键词渲染出对应的图像。
到了今年4月, 著名人工智能团队OpenAI 也发布了新模型 DALL·E 2代,该名称来源于著名画家达利(Dalí)和机器人总动员(Wall-E), 同样支持从文本描述生成效果良好的图像。
而很多读者对AI绘画开始产生特别的关注, 或许是从以下这幅AI作品闹出的新闻开始的:

这是一幅使用AI绘画服务 MidJourney 生成的数字油画,生成它的用户以这幅画参加美国科罗拉多州博览会的艺术比赛,夺得了第一名。这件事被曝光之后引发了网络上巨大的争论至今。
目前 AI绘画的技术仍在不断变化发展中,其迭代之快,完全可以用“日新月异”来形容。即使把今年年初的AI绘画和现在相比,。效果也有天壤之别。
在年初的时候,用Disco Diffusion可以生成一些很有氛围感的草图,但基本还无法生成人脸;仅仅2个月后,DALL-E 2已经可以生成准确的五官;现在,最强大的Stable Diffusion在画作的精致程度和作画速度上更是有了一个量级的变化。
AI绘画这项技术并不是近年才有的,但是今年以来,AI产出作品的质量以肉眼可见的速度日益提升,而效率也从年初的一个小时缩短到现在的十几秒。
在这个变化后面,究竟发生了什么事情?就让我们先全面回顾一下AI绘画的历史,再来理解一下这一年多来,AI绘画技术足以载入史册的突破发展。
AI绘画的历史
AI绘画的出现时间可能比很多人想象的要早。
计算机是上世纪60年代出现的,而就在70年代,一位艺术家哈罗德·科恩Harold Cohen(画家,加利福尼亚大学圣地亚哥分校的教授)就开始打造电脑程序“AARON”进行绘画创作。只是和当下AI绘画输出数字作品有所不同,AARON是真的去控制一个机械臂来作画的。
Harold对AARON的改进一直持续了几十年,直到他离世。在80年代的时候,ARRON“掌握”了三维物体的绘制;90年代时,AARON能够使用多种颜色进行绘画,据称直到今天,ARRON仍然在创作。
不过,AARON的代码没有开源,所以其作画的细节无从知晓,但可以猜测,ARRON只是以一种复杂的编程方式描述了作者Harold本人对绘画的理解——这也是为什么ARRON经过几十年的学习迭代,最后仍然只能产生色彩艳丽的抽象派风格画作,这正是 Harold Cohen 本人的抽象色彩绘画风格。 Harold用了几十年时间,把自己对艺术的理解和表现方式通过程序指导机械臂呈现在了画布上。

左:ARRON和哈罗德·科恩;右:ARRON 在 1992 年的创作作品
尽管难说AARON如何智能,但作为第一个自动作画且真的在画布上作画的程序,给予它一个AI作画鼻祖的称号,倒也符合其身份。
2006年,出现了一个类似ARRON的电脑绘画产品 The Painting Fool。它可以观察照片,提取照片里的块颜色信息,使用现实中的绘画材料如油漆、粉彩或者铅笔等进行创作。
以上这两个例子算是比较“古典”方式的电脑自动绘画,有点像一个学步的婴儿,有一点样子,但从智能化的角度来看是相当初级的。
而现在,我们所说的"AI绘画"概念,更多指的是基于深度学习模型来进行自动作图的计算机程序。这个绘画方式的发展其实是比较晚的。
在2012年Google两位大名鼎鼎的AI大神吴恩达和Jef Dean进行了一场空前的试验,联手使用1.6万个CPU训练了一个当时世界上最大的深度学习网络,用来指导计算机画出猫脸图片。当时他们使用了来自youtube的1000万个猫脸图片,1.6万个CPU整整训练了3天,最终得到的模型,令人振奋地可以生成一个非常模糊的猫脸。
在今天看起来,这个模型的训练效率和输出结果都不值一提。但对于当时的AI研究领域,这是一次具有突破意义的尝试,正式开启了深度学习模型支持的AI绘画这个“全新”研究方向。
在这里我们稍微讲一点技术细节:基于深度学习模型的AI绘画究竟有多麻烦呢,为什么2012年已经很现代水平的大规模计算机集群耗时多天的训练只能得出一点可怜的结果?
读者们或许有个基本概念,深度学习模型的训练简单说来就是利用外部大量标注好的训练数据输入,根据输入和所对应的预期输出,反复调整模型内部参数加以匹配的过程.
那么让AI学会绘画的过程,就是构建已有画作的训练数据,输入AI模型进行参数迭代调整的过程。
一幅画带有多少信息呢?首先就是长x宽个RGB像素点。让计算机学绘画,最简单的出发点是得到一个输出有规律像素组合的AI模型。
但RGB像素组合一起的并非都是画作,也可能只是噪点。一副纹理丰富、笔触自然的画作有很多笔画完成,涉及绘画中每一笔的位置、形状、颜色等多个方面的参数,这里涉及到的参数组合是非常庞大的。而深度模型训练的计算复杂度随着参数输入组合的增长而急剧增长……大家可以理解这个事情为啥不简单了。
在吴恩达和Jeff Dean开创性的猫脸生成模型之后,AI科学家们开始前赴后继投入到这个新的挑战性领域里。在2014年,AI学术界提出了一个非常重要的深度学习模型,这就是大名鼎鼎的对抗生成网络GAN(Generative Adverserial Network,GAN).
正如同其名字“对抗生成”, 这个深度学习模型的核心理念是让两个内部程序“生成器(generator)”和“判别器(discriminator)”互相PK平衡之后得到结果。
GAN模型一问世就风靡AI学术界,在多个领域得到了广泛的应用。它也随即成为了很多AI绘画模型的基础框架,其中生成器用来生成图片,而判别器用来判断图片质量。GAN的出现大大推动了AI绘画的发展。
但是,用基础的GAN模型进行AI绘画也有比较明显的缺陷,一方面是对输出结果的控制力很弱,容易产生随机图像,而AI艺术家的输出应该是稳定的;另外一个问题是生成图像的分辨率比较低。
分辨率的问题还好说, GAN在“创作”这个点上还存在一个死结, 这个结恰恰是其自身的核心特点:根据GAN基本架构,判别器要判断产生的图像是否和已经提供给判别器的其他图像是同一个类别的,这就决定了在最好的情况下,输出的图像也就是对现有作品的模仿,而不是创新……
在对抗生成网络GAN之外,研究人员也开始利用其他种类的深度学习模型来尝试教AI绘画。
一个比较著名的例子是2015年Google发布的一个图像工具深梦(Deep Dream)。深梦发布了一系列画作,一时吸引了很多眼球。谷歌甚至为这个深梦的作品策划了一场画展。
但如果较真一下,深梦与其说是AI绘画,更像是一个高级AI版滤镜。
和作品不尴不尬的Deep Dream相比,Google更靠谱的是2017年成千张手绘简笔画图片训练的一个模型,AI通过训练能够绘制一些简笔画。(Google,《A Neural Representation of Sketch Drawings》)
这个模型之所以受到广泛关注有一个原因,Google把相关源代码开源了,因此第三方开发者可以基于该模型开发有趣的AI简笔画应用。一个在线应用叫做 “Draw Together with a Neural Network”,随意画几笔,AI就可以自动帮你补充完整个图形。
值得注意的是,在AI绘画模型的研究过程中,各互联网大厂成了主力,除了上述Google所做的研究, 比较有名的是2017年7月,Facebook联合罗格斯大学和查尔斯顿学院艺术史系三方合作得到的新模型,号称创造性对抗网络(CAN,Creative Adversarial Networks)
(Facebook,《CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms》)
从下图的作品集可以看出,这个创造性对抗网络CAN在尝试输出一些像是艺术家作品的图画,它们是独一无二的,而不是现存艺术作品的仿品。

CAN模型生成作品里所体现的创造性让当时的开发研究人员都感到震惊,因为这些作品看起来和艺术圈子流行的抽象画非常类似。于是研究人员组织了一场图灵测试,请观众们去猜这些作品是人类艺术家的作品,还是人工智能的创作。
结果,53%的观众认为CAN模型的AI艺术作品出自人类之手,这在历史上类似的图灵测试里首次突破半数。
但CAN这个AI作画,仅限于一些抽象表达,而且就艺术性评分而言,还远远达不到人类大师的水平。更不用说创作出一些写实或者具象的绘画作品了,不存在的。
其实一直到2021年初,OpenAI发布了广受关注的DALL-E系统,其AI绘画的水平也就一般,下面是DALL-E画一只狐狸的结果,勉强可以辨别。

但值得注意的是,到了DALL-E这里,AI开始拥有了一个重要的能力,那就是可以按照文字输入提示来进行创作了!
接下来,我们继续去探求本文一开始提出的问题。不知各位读者是否有同感,自今年以来,AI绘画的水平突然大涨,和之前的作品质量相比有本质的飞跃,恍然有种一日不见如隔三秋的感觉。
事出必有妖. 究竟发生了什么情况? 我们慢慢道来.
AI绘画何以突飞猛进
在很多科幻电影或剧集里,往往会有这么一幕:主角和特别有科幻感的电脑AI说了一句话,然后AI生成了一个3D影像,用VR/AR/全息投影的方式呈现在主角面前。
抛开那些酷炫的视觉效果包装,这里的核心能力是,人类用语言输入,然后电脑AI理解人类的表达,生成一个符合要求的图形图像,展示给人类。
仔细一想,这个能力最基础的形式,就是一个AI绘画的概念嘛。(当然,从平面绘画到3D生成还稍有一点距离,但相比于AI凭空创作一幅具象有意义的绘画作品的难度,从2D图自动生成对应的3D模型就不是一个量级上的问题。)
所以,无论是用说话控制,还是更玄乎的脑电波控制,科幻影视中的酷炫场景实际上描述了一种AI能力,那就是把“语言描述”通过AI理解自动变为了图像。目前语音自动识别文本的技术已经成熟至极,所以这本质上就是一个从文本到图像的AI绘画过程。
其实挺牛X的,仅靠文字描述,没有任何参考图片,AI就能理解并自动把对应内容给画出来了,而且画得越来越好!这在昨天还感觉有点远的事情,现在已真真切切出现在所有人的面前。
这一切到底怎么发生的呢?
首先要提到一个新模型的诞生。还是前面提到的OpenAI团队,在2021年1月开源了新的深度学习模型 CLIP(Contrastive Language-Image Pre-Training)。一个当今最先进的图像分类人工智能.。
CLIP训练AI同时做了两个事情,一个是自然语言理解,一个是计算机视觉分析。它被设计成一个有特定用途的能力强大的工具,那就是做通用的图像分类,CLIP可以决定图像和文字提示的对应程度,比如把猫的图像和“猫”这个词完全匹配起来、
CLIP模型的训练过程,简单的说,就是使用已经标注好的“文字-图像”训练数据,一方面对文字进行模型训练,一方面对图像进行另一个模型的训练,不断调整两个模型内部参数,使得模型分别输出的文字特征值和图像特征值能让对应的“文字-图像”经过简单验证确认匹配。
关键的地方来了,其实呢,之前也有人尝试过训练“文字-图像”匹配的模型,但CLIP最大的不同是,它搜刮了40亿个“文字-图像”训练数据!通过这天量的数据,再砸入让人咂舌的昂贵训练时间,CLIP模型终于修成正果。
聪明的读者会问,这么多的“文字-图像”标记是谁做的呢?40亿张啊,如果都需要人工来标记图像相关文字,那时间成本和人力成本都是天价。而这正是CLIP最聪明的地方,它用的是广泛散布在互联网上的图片!
互联网上的图片一般都带有各种文本描述,比如标题、 注释,甚至用户打的标签,等等,这就天然的成为了可用的训练样本。用这个特别机灵的方式,CLIP的训练过程完全避免了最昂贵费时的人工标注,或者说,全世界的互联网用户已经提前做了标注工作了。
CLIP功能强大,但无论如何,它第一眼看上去,和艺术创作似乎没啥关系。
但就在CLIP开源发布几天后,一些机器学习工程师玩家就意识到,这个模型可以用来做更多的事情. 比如Ryan Murdock,想出了如何把其他AI连接到CLIP上,来打造一个AI图像生成器。Ryan Murdock在接受采访时说:“在我把玩它几天后,我意识到我可以生成图像。”
最终他选择了BigGAN,一个GAN模型的变种,并将代码发布为Colab笔记The Big Sleep。
(注:Colab Notebook是Google提供的非常方便的Python Notebook交互式编程笔记本在线服务,背后是Google云计算的支持。略懂技术的用户可以在一个类似笔记本的Web界面上编辑运行Python脚本并得到输出。重要的是,这个编程笔记是可以分享的)
Big Sleep创作的图画其实略诡异和抽象, 但这是一个很好的开始。

随后,西班牙玩家@RiversHaveWings在此基础上发布了CLIP+VQGAN的版本和教程,这个版本通过Twitter被广为转发传播,引起了AI研究界和爱好者们的高度关注。而这个ID背后,正是现在所被熟知的计算机数据科学家 Katherine Crowson。
在之前,类似VQ-GAN这样的生成工具在对大量图像进行训练后,可以合成类似的新图像,然而,如读者还有印象,前面说过,GANs类型的模型本身并不能通过文字提示生成新图像,也不擅长创作出全新的图像内容。
而把CLIP嫁接到GAN上去生成图像,这其中的思路倒也简单明了:
既然利用CLIP可以计算出任意一串文字和哪些图像特征值相匹配,那只要把这个匹配验证过程链接到负责生成图像的AI模型(比如这里是VQ-GAN) ,负责生成图像的模型反过来推导一个产生合适图像特征值,能通过匹配验证的图像,不就得到一幅符合文字描述的作品了吗?
有人认为CLIP+VQGAN是自2015年Deep Dream以来人工智能艺术领域最大的创新。而美妙的是,CLIP+VQGAN对任何想使用它们的人来说都是现成的。按照Katherine Crowson的线上教程和Colab Notebook,一个略懂技术的用户可以在几分钟内运行该系统。
有意思的是,上一章也提到,在同一个时间(2021年初),开源发布CLIP的OpenAI团队也发布了自己的图像生成引擎DALL-E。DALL-E内部也正是用了CLIP,但DALL-E并不开源!
所以论社区影响力和贡献,DALL-E完全不能和CLIP+VQGAN的开源实现发布相比,当然,开源CLIP已经是OpenAI对社区做出的巨大贡献了。
说到开源贡献,这里还不得不提到LAION。
LAION是一个跨全球的非营利机器学习研究机构,今年3月开放了当前最大规模的开源跨模态数据库LAION-5B,包含接近60亿(5.85 Billion)个图片-文本对,可以被用来训练所有从文字到图像的的生成模型,也可以用于训练 CLIP这种用于给文本和图像的匹配程度打分的模型,而这两者都是现在 AI 图像生成模型的核心。
除了提供以上的海量训练素材库,LAION 还训练 AI 根据艺术感和视觉美感,给LAION-5B 里图片打分,并把得高分的图片归进了一个叫 LAION-Aesthetics 的子集。
事实上, 最新的AI绘画模型包括随后提到的AI绘画模型王者 Stable Diffusion都是利用LAION-Aesthetics这个高质量数据集训练出来的。
CLIP+VQGAN 引领了全新一代AI图像生成技术的风潮,现在所有的开源 TTI(Text to Image, 文本文本生成图像)模型的简介里都会对 Katherine Crowson 致谢,她是当之无愧的全新一代AI绘画模型的奠基者。
技术玩家们围绕着CLIP+VQGAN开始形成社区,代码不断有人做优化改进,还有Twitter账号专门收集和发布AI画作。而最早的践行者Ryan Murdoch 还因此被招募进了Adobe担任机器学习算法工程师。
不过这一波AI作画浪潮的玩家主要还是AI技术爱好者。
尽管和本地部署AI开发环境相比,在Golab Notebooks上跑CLIP+VQGAN的门槛相对而言已经比较低,但毕竟在Colab申请GPU运行代码并调用AI输出图片,时不时还要处理一下代码报错,这不是大众化人群特别是没有技术背景的艺术创作者们可以做的。而这也正是现在 MidJourney 这类零门槛的傻瓜式AI付费创作服务大放光彩的原因。
但激动人心的进展到这里还远没结束。细心的读者注意到,CLIP+VQGAN这个强力组合是去年初发布并在小圈子传播的,但AI绘画的大众化关注,如开篇所说,则是在今年初开始,由Disco Diffusion这个线上服务所引爆。这里还隔着大半年的时间。是什么耽搁了呢?
一个原因是CLIP+VQGAN模型所用到的图像生成部分,即GAN类模型的生成结果始终不尽如人意。
AI人员注意到了另外一种图像生成方式。如果复习一下GAN模型的工作原理,其图像输出是内部生成器和判断器的PK妥协结果。但还有另外一种思路,那就是Diffusion模型(扩散化模型)。
Diffusion这个词也很高大上,但基本原理说出来大家都能理解,其实就是“去噪点”。对,就是我们熟悉的手机拍照(特别是夜景拍照)的自动降噪功能。如果把这个去噪点的计算过程反复进行,在极端的情况下,是不是可能把一个完全是噪声的图片还原为一个清晰的图片呢?

靠人当然不行,简单的去噪程序也不可能,但是基于AI能力去一边“猜”一边去噪,倒是可行的。
这就是Diffusion扩散化模型的基本思路。
Diffusion扩散化模型目前在计算机视觉领域的影响力越来越大,它能够高效合成视觉数据,图片生成完全击败了GAN模型,而在其他领域如视频生成和音频合成也展现出了不俗的潜力。
今年初被大众首先熟知的AI绘画产品Disco Diffusion,正是第一个基于CLIP + Diffusion模型的实用化AI绘画产品。
但Disco Diffusion的缺点还是有些明显,如身为专业艺术家的 Stijn Windig 反复尝试了Disco Diffusion,认为 Disco Diffusion 并没有取代人工创作的能力,核心原因有2点:
不过 Stijn Windig 还是对AI绘画的发展持乐观态度,他觉得尽管直接利用 Disco Diffusion 进行商业化创作还不可行,但作为一种灵感参考还是非常好的:“……我发现它更适合作为一个创意生成器使用。给一个文字提示,它返回一些图片能激发我的想象力,并可以作为草图用来在上面绘画。”
其实从技术上来说, Stijn提出的两大痛点实际上都是因为Diffusion扩散模型的一个内在缺点, 这就是反向去噪生成图片的迭代过程很慢,模型在像素空间中进行计算,这会导致对计算时间和内存资源的巨大需求,在生成高分辨率图像时变得异常昂贵。(像素空间, 有点专业化的说法, 实际上就是说模型直接在原始像素信息层面上做计算)
因此对于大众应用级的平台产品,这个模型无法在用户可以接受的生成时间里去计算挖掘更多的图像细节,即便那种草稿级别的作图,也需要耗费Disco Diffusion以小时计算的时间。
但无论如何,Disco Diffusion给出的绘画质量,相对于之前的所有AI绘画模型,都是碾压式的超越,而且已经是大部分普通人无法企及的作画水平了,Stijn的挑刺只是站在人类专业创作的高点提出的要求。
但是,Stijn同学恐怕万万没想到,他所指出的AI绘画两大痛点,还没过几个月,就被AI研究人员近乎完美的解决了!
讲到这里,当当当当,当今世界最强大的AI绘画模型Stable Diffusion终于闪亮登场了!
Stable Diffusion今年7月开始测试,它非常好的解决了上述痛点。
实际上Stable Diffusion和之前的Diffusion扩散化模型相比,重点是做了一件事,那就是把模型的计算空间,从像素空间经过数学变换,在尽可能保留细节信息的情况下降维到一个称之为潜空间(Latent Space)的低维空间里,然后再进行繁重的模型训练和图像生成计算。
这个"简单"的思路转化,带来了多大的影响呢?
基于潜空间的Diffusion模型与像素空间Diffusion模型相比,大大降低了内存和计算要求。比如Stable Diffusion所使用的潜空间编码缩减因子为8,说人话就是图像长和宽都缩减8倍,一个512x512的图像在潜空间中直接变为64x64,节省了8x8=64倍的内存!
这就是Stable Diffusion之所以又快又好的原因,它能快速(以秒计算)生成一张饱含细节的512x512图像,只需要一张消费级的8GB 2060显卡即可!
读者可以简单算一下,如没有这个空间压缩转换,要实现Stable Diffusion这样的秒级图像生成体验,则需要一张8Gx64=512G显存的超级显卡。按照显卡硬件的发展规律来看,消费级显卡达到这个显存恐怕是8~10年后的事情。
而AI研究人员一个算法上的重要迭代,把10年后我们才可能享受到的AI作画成果直接带到了当下所有普通用户的电脑前!
所以目前大家对AI绘画的进展感到吃惊是完全正常的,因为从去年到今年,AI绘画的技术确实出现了连续的突破性的进展,从CLIP模型基于无需标注的海量互联网图片训练大成,到CLIP开源引发的AI绘画模型嫁接热潮,然后找到了Diffusion扩散化模型作为更好的图像生成模块,最后使用潜空间降维的改进方法解决了Diffusion模型时间和内存资源消耗巨大的问题……这一切的一切,让人目不暇接,可以说AI绘画在这一年间,变化是以天计算的!
而在这个过程中,最幸福的莫过于所有AI技术爱好者和艺术创作者们。大家亲眼目睹着停滞了多年的AI绘画水平以火箭般的速度冲到了顶峰。毫无疑问,这是AI发展历史上的一个高光时刻。
而对所有普通用户来说,最开心的,当然是享受到了利用Stable Diffusion或者MidJourney这样的当今顶级作画AI去生成专业级别画作的巨大乐趣。
有趣的是,Stable Diffusion的诞生还和前面提到的两位先驱Katherine Crowson 和Ryan Murdoch 有关。他们成为了一个去中心化组织的AI开源研发团队EleutherAI的核心成员。虽然自称草根团队,但EleutherAI在超大规模预言模型和AI图像生成领域目前都已经是开源团队的佼佼者。
正是EleutherAI作为技术核心团队支持了Stability.AI这一家创始于英国伦敦的AI方案提供商。这些有理想的人们聚在一起,基于以上这些最新的AI绘画技术突破,推出了当今最强大的AI绘画模型Stable Diffusion。重要的是,Stable Diffusion按照承诺,已经在8月完全开源!这个重要的开源让全世界的AI学者和AI技术爱好者感动得痛哭流涕。Stable Diffusion一经开源,就始终霸占着GitHub热榜第一。
Stability.AI彻底履行了它官网首页的Slogan “AI by the people,for the people”,必须给予一个大大的赞.
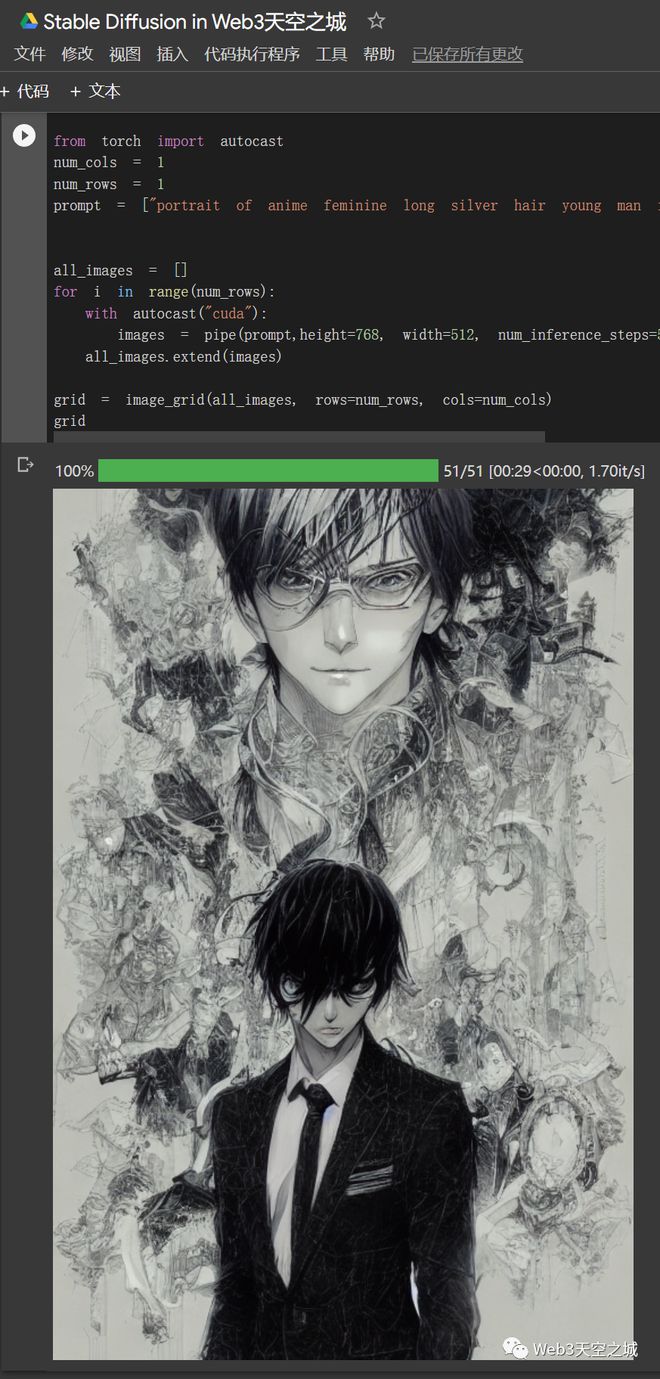
下图是作者线上运行的Stable Diffusion,感谢开源!话说这个AI生成的自带光环的日漫小哥是相当的帅气:)
顶级AI绘画模型的PK:Stable Diffusion vs. MidJourney
作者在之前文章里已经介绍了MidJourney这个在线AI作画神器,它最大的优点就是零门槛的交互和非常好的输出结果。创作者无需任何技术背景就能利用基于Discord的MidJourney bot进行对话式绘画创作(恩,当然,全英文)。
从输出风格上看,MidJourney非常明显针对人像做了一些优化,用多了后, MidJourney的风格倾向也比较明显(作者在MidJourney上花了数百刀的计算资源尝试了各种主题创作后的第一手感受),说得好听是比较细腻讨巧,或者说,比较油腻一点点。
而Stable Diffusion的作品,就明显的更淡雅一些,更艺术化一些。
以下是作者使用了同一种文字描述在这两大平台上创作的AI作品对比,读者不妨直接感受一下。(注:以下生成画作均有完全版权,单独转载请注明来源)
Stable Diffusion(左)vs.MidJourney(右):
树屋

柴油朋克风的城市

魔兽世界主城奥格瑞玛

盔甲狼骑士

碧蓝幻想风格漫画少女

浪漫写实主义美女油画(风格参考丹尼尔·戈尔哈茨,美国画家)

带有狭长走道的迷宫般老城市建筑

哪种风格更好?其实萝卜青菜各有所爱。
因为做过针对性的优化,如要出人像图或者糖水风格美图用MidJourney更方便。但比较了多张作品后,作者认为Stable Diffusion还是明显技高一筹,无论从艺术表达上还是风格变化的多样性上。
不过,MidJourney这几个月的迭代是有目共睹的快(毕竟是付费服务,很赚钱很有动力啊), 加上Stable Diffusion的完全开源,预计相关技术优势会很快被吸收进MidJourney。而另一方面,Stable Diffusion模型的训练还在持续进行中,我们可以非常期待,未来版本的Stable Diffusion模型也将百尺竿头更进一步。
对所有的创作者用户而言, 这都是天大的好事。
AI绘画的突破对人类意味着什么
2022年的AI领域,基于文本生成图像的AI绘画模型是风头无两的主角。从2月份的Disco Diffusion开始,4月DALL-E 2和MidJourney邀请内测,5月和6月Google发布两大模型Imagen 和Parti(不开放内测只有论文,感觉略水),然后7月底,Stable Diffusion横空出世……
真的让人眼花缭乱。也勿怪作者在上篇文章里感慨,怎么稍不注意AI绘画的水平就突飞猛进到如此地步,事实上,确实就是在这一年半载里,AI绘画发生了革命性的、甚至可以说历史上会留名的突破性进展。
而接下去的时间里,AI绘画,或者更广泛的,AI生成内容领域(图像、声音、视频、3D内容等)还会发生什么,让人充满了遐想和期待。
但不用等待未来,体验了当下以Stable Diffusion为代表的最先进AI绘画模型所能触达的艺术高度,我们已经基本可以确认,“想象力”和“创造力”这两个曾经充满着神秘主义的词汇,同时也是人类最后的骄傲,其实也是可以被技术解构的。
对人类灵魂神圣至上说法的拥护者而言,当今AI绘画模型所展现的创造力,是一种对信仰的无情打击。所谓灵感、创造力、想象力,这些充满着神性的词,即将(或者已经)被超级算力+大数据+数学模型的强力组合无情打脸了。
事实上,类似Stable Diffusion这种AI生成模型的一个核心思路,或者说很多深度学习AI模型的核心思路,就是把人类创作的内容,表示为某个高维或者低维数学空间里的一个向量(更简单的理解,一串数字)。
如果这个“内容->向量”的转化设计足够合理,那么人类所有的创作内容都可以表示为某个数学空间里的部分向量而已。而存在于这个无限的数学空间里的其他向量,正是那些理论上人类可能创造,但尚未被创造出来的内容。通过逆向的“向量->内容”的转换,这些还没被创造的内容就被AI挖掘出来了。
这正是目前MidJourney、Stable Diffusion这些最新AI绘画模型所做的事情。AI可以说是在创作新的内容,也可以说是新绘画作品的搬运工。AI产生的新绘画作品在数学意义上一直客观存在,只是被AI通过很聪明的方式,从数学空间里还原出来,而已。
“文章本天成, 妙手偶得之”。
这句话放在这里非常合适。这“天”,是那个无限的数学空间;而这“手”,从人类换成了AI。数学真是世界至高法则。
目前最新AI绘画的“创造力”开始追赶甚至几已比肩人类,这或许进一步打击了人类的尊严,从围棋阿法狗开始,人类在“智慧”这个点的尊严领地已经越来越小,而AI绘画的突破性进展则进一步把人类“想象力”和“创造力”的尊严都打碎了——或许还没完全破碎,但已经充满裂痕摇摇欲坠。
作者一直对人类的科技发展保持某种中性看法:尽管我们寄望于科技让人类的生活变得更美好,但事实上正如核弹的发明,有些科学技术的出现是中性的,也可能是致命的。完全取代人类的超级AI从实践来看似乎是一件越来越可能的事情。人类需要思考的是,在不太远的将来,我们在所有领域面对AI都落荒而逃的时候,如何保持对世界的主导权。
有个朋友说的很对,如果AI最终学会了写代码——似乎没有什么必然的壁垒在阻止这件事的发生——那么电影《终结者》的故事或许就要发生了。如果这样太悲观,那么人类至少要考虑,如何与一个超越自己所有智慧和创造力的AI世界相处。
当然咯,乐观的角度而言,未来的世界只会更美好:人类通过AR/VR接入统一的或者个人的元宇宙,人类主人只要动动嘴皮子,无所不能的AI助理就能根据要求自动生成内容,甚至直接生成可供人类体验的故事/游戏/虚拟生活。
这是一个更美好的盗梦空间,还是一个更美好的黑客帝国?(笑)
无论如何,今天我们见证的AI绘画能力的突破和超越,正是这条不归路的第一步。
One More Thing
说个题外话作为结尾。尽管还没出现,但应该就在这两年,我们可以直接让AI生成一本指定风格的完整长篇小说,特别是那些类型化的作品,比如《斗破苍穹》《凡人修仙传》这样的玄幻小说,还可以指定长度,指定女主角个数,指定情节倾向性,指定悲情程度和热血程度,甚至xx程度,AI一键生成。
这完全不是天方夜谭,考虑到AI绘画这一年坐火箭般的发展速度,作者甚至觉得这一天就近在眼前。
目前还没有AI模型可以生成足够感染力和逻辑性的长篇文学内容,但从AI绘画模型气势汹汹的发展态势来看,不久的将来AI生成高质量的类型文学作品几乎已是板上钉钉的事情,理论上没有任何的疑问.
这样说或许打击了那些辛苦码字的网文作者,但作为一个技术爱好者和玄幻小说爱好者,作者对这一天的到来还是有些期待的:从此再也不需催更,也不需要担心连载作者的写作状态了;更美好的是,看到一半如觉得不爽,还可以随时让AI调整后续情节方向重新生成再继续看……
若你还不确定这样的一天即将到来,我们可以求同存异,一起等待。
最后分享一组作者用stable diffusion生成的细节完全不同、风格又完全一致,质量还永远保持满格的“带有狭长走道的城市迷宫老建筑区”系列。看着这些精美的AI作品,作者只有一种感觉,AI创作有“灵魂”了,不知读者们,是否有同感?





本文来自微信公众号:Web3天空之城(ID:gh_a702b8d21cdf),作者:城主
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系 hezuo@huxiu.com